Everyone is hating on the the MIT study published in July, which claimed that 95% of organizations are getting a zero percent return on their genAI investments. This report, published by the MIT Media Lab, has been extensively debated by both critics and advocates, including some of the most recognized and respected voices on the AI circuit.
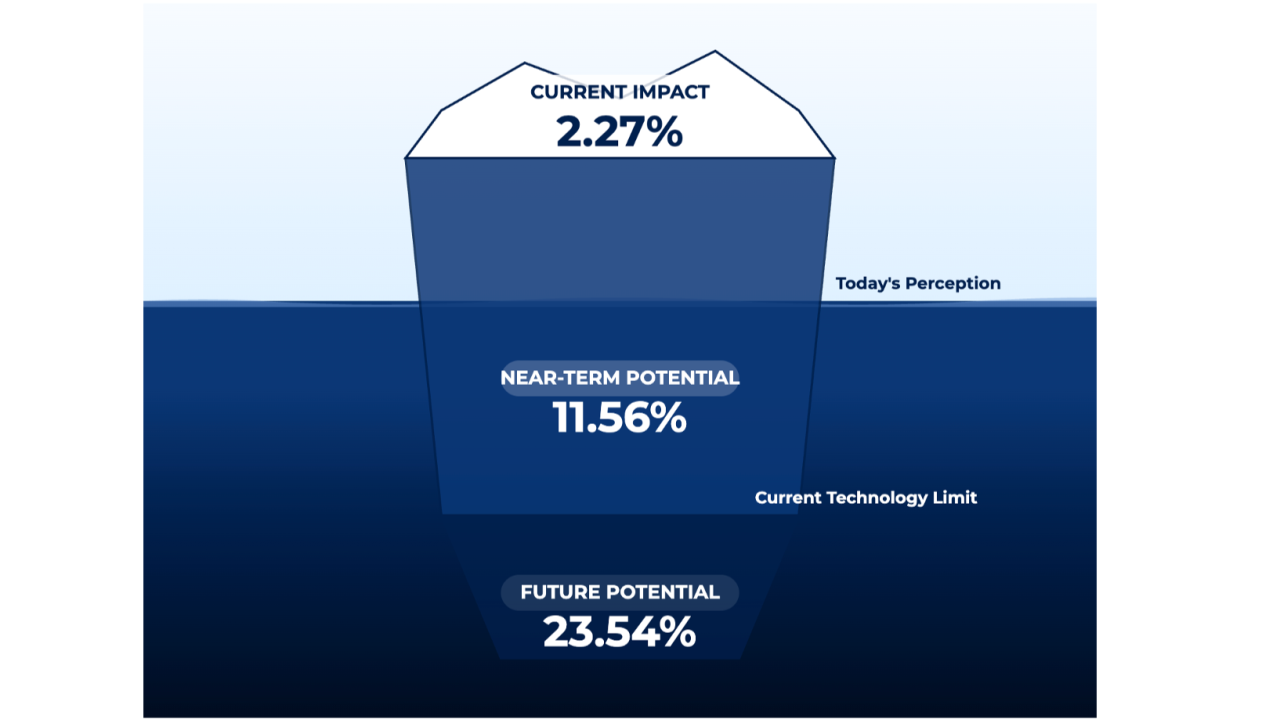
The 2.27% current impact represents the portion of total possible value that organizations are realizing today from agentic AI. (iceberg.mit.edu)
"Despite $30-$40 billion in enterprise investment into GenAI, this report uncovers a surprising result in that 95% of organizations are getting zero return.... Just 5% of integrated AI pilots are extracting millions in value, while the vast majority remain stuck with no measurable P&L Impact."
That's a pretty spectacular claim. I certainly agree that finding the return on investment (ROI) is harder than expected, and I have seen teams swirl looking for that spectacular 2-4x ROI on one or just a handful of use cases. I think this study also ignites fear in all of us product companies looking to really make a difference in mortgage. We don't really want to talk about how hard it is to find meaningful and lasting change. So let's just put that out in the open.
The main point is to argue that the key differentiator between success and failure are systems that learn. It argues that the classic ChatGPT model of assistive or conversational AI is great for short thinking tasks, and falls apart for long thinking due to lack of memory. It argues that agents are necessary to achieve real organizational value, and that there is a window of about 18 months to settle on partnerships that will help organizations really capitalize on the AI advantage.

So basically it's a study to put data behind the claim that agents are the key to real value unlock, and that the time is now to seize the advantage. That's the bottom line, and I think it's useful. Yes, there are many reasons to hate on the study, but the bottom line strikes me as mostly valid.
The study was based on 52 interviews across "enterprise stakeholders", a "systematic analysis" of about 300 public AI initiatives, and surveys with 152 leaders. Not a super big or scientific study from my perspective. But still, let's put away the pitchforks. It's better than nothing, right? I think some of the best insights are revealed in the quotes.
The report had a pretty high bar for the definition of success. Said in my words, success is defined as meaningful impact on the P&L, measured six months post deployment. Keep in mind, this wasn't actually measured, this was based on what those interviewed or surveyed said.
I've been a large scale commercial software product manager for a lot of my career. I've had many glorious successes and just as many spectacular failures. By this definition, I'm sure at least some of my successes would be failures. And if you consider what it takes to move in federal, I think success would be even more scarce. This definition applies to a narrow spectrum of small, turnkey, commercial solutions where you can turn it on and see immediate P&L impact.
While this is definitely the goal for all of us, I'm just not sure it's a realistic definition for the rest of the world. Or maybe I'm the one with the outdated perspective (ok, ok, probably it's a me problem and I am being defensive). I do base a lot of my experience on what the process has been like in the past. I certainly agree that in a world where we can go concept to cash in a week, we should be able to move the needle on the P&L in a matter of months.
The authors are from the Networked AI Agents in Decentralized Architecture (NANDA) team at MIT. NANDA is a research initiative focused on how agentic, networked AI systems will impact organizational performance. They conduct research and host events that explore the future of what they call the agentic web, defined as "billions of specialized AI agents collaborating across a decentralized architecture".
Agentic AI according to NANDA researchers is the class of systems that embeds persistent memory and iterative learning by design, directly addressing what they see as the learning gap in assistive AI solutions like ChatGPT and wrapper based AI solutions.
That is also a high bar, in terms of the definition of an AI agent. In my classes and workshops, I typically define an AI agent as having four key characteristics, the ability to:
I adapted this definition from Jensen at NVIDIA GTC earlier this year, so admittedly maybe it's time for me to evolve my definition, it has been about four months or so. I like my definition because its easy to communicate and remember, and it is easy to contrast from assistive or conversational AI. But just because it's easy, doesn't make it right. NANDA has a much more complicated perspective, resting on a foundation of what they call decentralized AI.

This idea of an agentic web resting upon a network of decentralized AI systems is complicated, and requires a level of technical sophistication that I really don't have. But I get the concept, and it makes theoretical sense. It just seems... really hard. It requires a lot of humans (?) to do a lot of sophisticated things around the world. Meanwhile in mortgage we are still just trying to figure out agents beyond the call center, research functions, and development acceleration (where agents are well established).
This I did find useful. It was a little section that did a good job painting the picture of common myths in genAI, some of which I agreed with, and I did stop and think about all of them.
So cutting through all the jargon and the NANDA rabbit holes I explored through my study of the study, here's what I take away from all this for us in mortgage AI.
By Tela Mathias, Chief Nerd and Mad Scientist, PhoenixTeam




