Introducing Large Language Models to Traditional Machine Learning Operations
Machine learning (ML) operations (MLOps) is the set of practices, tools, and associated culture that bridges the gap between building ML models and running them reliably in production. MLOps is as much about science and engineering as it is about systems thinking. Some of learnings in this article come from a session at GTC focused on explaining why MLOps is needed, and what changes with MLOps when generative technologies are introduced.
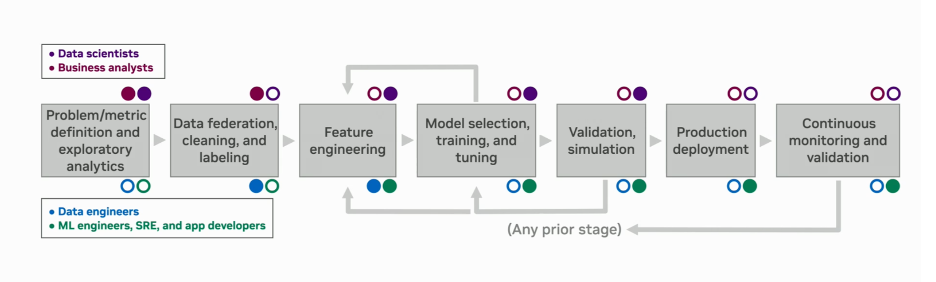
A traditional MLOps approach starts with problem definition and culminates with continuous monitoring and validation, like most (good) product development lifecycles.
Why does MLOps matter?
Let’s start with why this matters. Especially in financial services, we have to be able to answer at least four key questions:
What is this model doing and where is it in production?
What was it trained and validated on, and is production still consistent with that?
Who approved it, who owns it now, and what changed since approval?
Is it still performing safely, fairly, and within policy, and what happens if it does not?
MLOps is at the heart of many of these questions. Model management is not new to us in mortgage and has significantly evolved from the early days of automated underwriting and securitization. With the financial crisis of 2008, model risk became increasingly central to fair lending, risks assumptions, and stress testing. The introduction of generative models into our ecosystem only increases the importance of good operational practices around this new kind of ML system, hence the idea of MLOps as central to the new AI-powered mortgage ecosystem.
Famous Examples of MLOps Gone Wrong
There are many examples of MLOps "gone wrong", or cases where an engineering operations focus could have created better outcomes. A few examples mentioned at the NVIDIA conference:
Ariane 5 Flight 501 (1996): Ariane 5 was a European rocket, and on its first launch it went off course and had to be destroyed less than a minute after takeoff. Part of its guidance software accepted a value larger than it was built to handle, causing the system to fail at a critical moment. The MLOps lesson is that a system can break fast when real-world conditions go beyond what the system was designed and tested for.
Mars Climate Orbiter (1999): NASA intended for the Mars Climate Orbiter to, well, actually orbit Mars, but instead it burned up in the Martian atmosphere. One part of the system was using English measurement units and another was expecting metric units. The numbers appeared valid but in execution meant different things. The MLOps lesson is that a system can when different teams or tools are not using the same measurement rules.
Millennium Bridge (2000): Under pedestrian traffic shortly after it opened, London's Millennium Bridge swayed side to side much more than expected and had to be closed for safety reasons. Engineers found that once the bridge began moving under foot traffic, people naturally adjusted how they walked, these unexpected lateral forces unintentionally made the side-to-side motion worse. The MLOps lesson is that a system can seem fine in design and testing, then behave very differently once real people interact with it at scale.
Knight Capital (2012): A bad software rollout caused Knight Capital's core financial system to initiate huge numbers of unintended trades. During the first 45 minutes of trading, the system turned 212 customer orders into more than four million orders and led to more than $460 million in losses. This demonstrated that a system can fail not because the idea is wrong, but because a bad production rollout can make the live system behave in a completely different way than intended. The MLOps connection here is less about machine learning itself and more about how you safely release and control live decision systems.
Failure Through an MLOps Lens
It was helpful for me to see this diagram explained within the context of the spectacular failures as explained by serious MLOPs engineers.
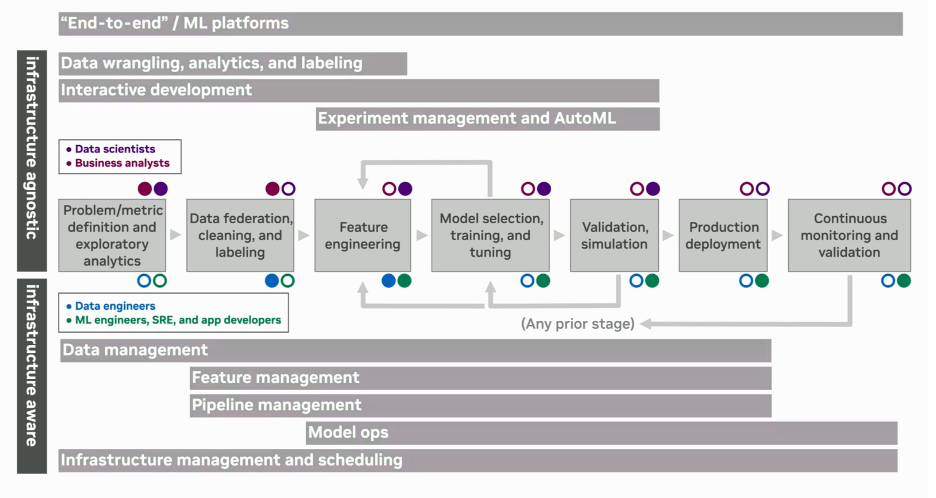
Looking at a robust MLOps framework like the one used at NVIDIA, we can pinpoint the failure points.
Ariane 5 failed because the live system encountered values outside what the software could handle. In this framework, that should have been caught by defining the operating limits early and then testing the system against extreme but plausible conditions during validation and simulation.
Mars was really an interface meaning problem: the numbers were there, but one side meant English units and the other meant metric. In this framework, that belongs first in data federation, cleaning, and labeling, where data definitions and contracts should be aligned, and then in validation and simulation, where those handoffs should be tested before deployment.
The bridge looked fine until real people started walking on it, which created a feedback loop nobody had fully accounted for. In this framework, that means you need stronger validation and simulation before launch, but also continuous monitoring and validation after release because some behaviors only appear in the real world at scale.
Knight Capital was mainly a bad production rollout problem. In this framework, the strongest controls should have been in production deployment, making sure the release was consistent and safe, and in continuous monitoring and validation, so the issue was detected and stopped immediately.
How MLOps Changes with Generative Models
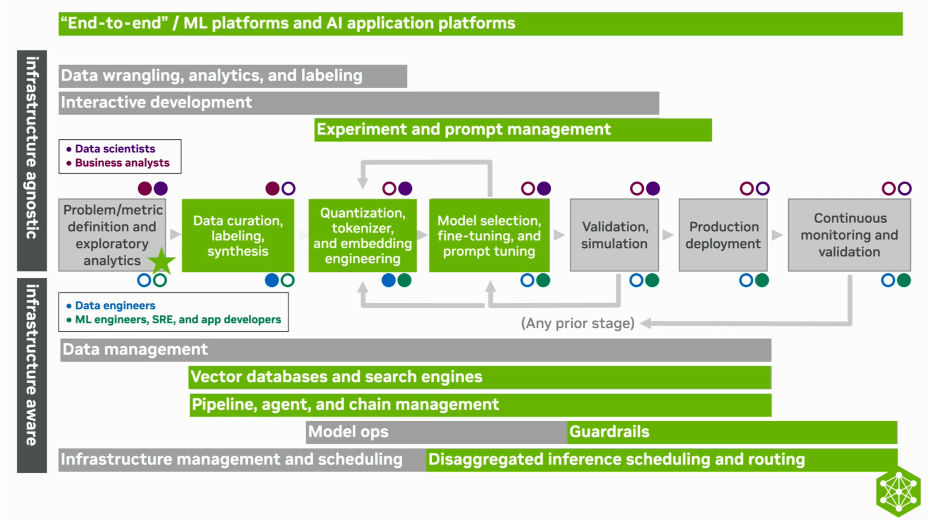
Generative models are simply a new and more complicated model to manage. Even a simple retrieval augmented generation (RAG) bot is actually a relatively complicated MLOps system.
We still start with problem definition, that hasn't changed. And we still have to make our data "ready" for use in retrieval. This data, which will be used to enrich and further contextualize the base knowledge of the large language model, has to be converted to vector embeddings, which requires, chunking, tokenization, and use of an embedding model. All steps in an MLOps pipeline flow. We should probably also store the original natural language data, yet another thing to manage. And don't forget change, how we govern the process of updating our embeddings is kind of a big deal. More MLOps.
We have this new problem of prompt management and evaluation, which requires golden standard data sets with both the questions and the answer (also called QA pairs for question and answer). It also requires us to have a good natural language versioning solution, again because the problem of change and optimization is a big deal. Prompts are a significant asset to understand, version, evaluate, test, optimize and control.
And of course model management, not exactly new in a generative scenario, but perhaps more fluid. Even if we are not training foundation models, we still have to preserve optionality, adapt the behavior of the model (perhaps going so far as to fine tune it), and customize how it behaves under real workloads and in the real world. More work with the intersections of prompting, data, and evaluation. Ensuring the model performs with edge cases, unanticipated scenarios, and over time (detecting and addressing model drift) would all be the purview of MLOps.
Although not expressly called out in our diagram above, latency management seems more significant with the addition of generative technologies. Users have come to expect instant answers, regardless of how complicated the request it. We have to think about when to offload workloads to an asynch process, when to use streaming so users can at least see the answer as it builds, paralellization.
Finally guardrails, again not exactly new to traditional MLOps, but something acutely important for understanding, controlling, and evidencing an AI system. Proving the responsible implementation, demonstrating safety, evidencing harm prevention - all essential to managing a good AI system, and all the purview of MLOps if you want it done well.
By Tela Mathias, CTO & Chief Nerd and Mad Scientist at PhoenixTeam
Accelerate Your Operations with AI-powered Expertise